
本书是关于如何从零开始构建大模型的指南,由畅销书作家塞巴斯蒂安• 拉施卡撰写,通过清晰的文字、图表和实例,逐步指导读者创建自己的大模型。在本书中,读者将学习如何规划和编写大模型的各个组成部分、为大模型训练准备适当的数据集、进行通用语料库的预训练,以及定制特定任务的微调。此外,本书还将探讨如何利用人工反馈确保大模型遵循指令,以及如何将预训练权重加载到大模型中。
编辑推荐
大佬作者倾力打造:GitHub项目LLMs-from-scratch(4万星)作者、大模型独角兽公司Lightning AI工程师倾力打造
零基础实战指南:只需Python基础,手把手教你从零实现类ChatGPT模型
行业大咖力荐:本书获得多位AI领域大咖的推荐,包括新浪微博首席科学家&AI研发部负责人张俊林,NLP知名博客“科学空间”博主苏剑林,GitHub高级工程师Benjamin Muskalla,Netflix资深科学家Cameron Wolfe,《设计机器学习系统》与AI Engineering作者Chip Huyen,FM Global高级数据科学家Vahid Mirjalili博士等
惊喜彩蛋DeepSeek:教你构建与优化推理模型的方法和策略
配套资源丰富:GitHub 4万星开源配套代码、YouTube配套视频教程
作者简介:
目录:
第 1章 理解大语言模型 1
1.1 什么是大语言模型 2
1.2 大语言模型的应用 3
1.3 构建和使用大语言模型的各个阶段 4
1.4 Transformer架构介绍 6
1.5 利用大型数据集 9
1.6 深入剖析GPT架构 11
1.7 构建大语言模型 13
1.8 小结 14
第 2章 处理文本数据 15
2.1 理解词嵌入 16
2.2 文本分词 18
2.3 将词元转换为词元ID 21
2.4 引入特殊上下文词元 25
2.5 BPE 29
2.6 使用滑动窗口进行数据采样 31
2.7 创建词元嵌入 37
2.8 编码单词位置信息 40
2.9 小结 44
第3章 编码注意力机制 45
3.1 长序列建模中的问题 46
3.2 使用注意力机制捕捉数据依赖关系 48
3.3 通过自注意力机制关注输入的不同部分 49
3.4 实现带可训练权重的自注意力机制 57
3.5 利用因果注意力隐藏未来词汇 66
3.6 将单头注意力扩展到多头注意力 74
3.7 小结 82
第4章 从头实现GPT模型进行文本生成 83
4.1 构建一个大语言模型架构 84
4.2 使用层归一化进行归一化激活 89
4.3 实现具有GELU激活函数的前馈神经网络 94
4.4 添加快捷连接 99
4.5 连接Transformer块中的注意力层和线性层 102
4.6 实现GPT模型 105
4.7 生成文本 110
4.8 小结 115
第5章 在无标签数据上进行预训练 116
5.1 评估文本生成模型 117
5.2 训练大语言模型 131
5.3 控制随机性的解码策略 137
5.4 使用PyTorch加载和保存模型权重 144
5.5 从OpenAI加载预训练权重 145
5.6 小结 152
第6章 针对分类的微调 153
6.1 不同类型的微调 154
6.2 准备数据集 155
6.3 创建数据加载器 159
6.4 初始化带有预训练权重的模型 163
6.5 添加分类头 166
6.6 计算分类损失和准确率 172
6.7 在有监督数据上微调模型 176
6.8 使用大语言模型作为垃圾消息分类器 182
6.9 小结 184
第7章 通过微调遵循人类指令 185
7.1 指令微调介绍 186
7.2 为有监督指令微调准备数据集 187
7.3 将数据组织成训练批次 190
7.4 创建指令数据集的数据加载器 201
7.5 加载预训练的大语言模型 204
7.6 在指令数据上微调大语言模型 207
7.7 抽取并保存模型回复 211
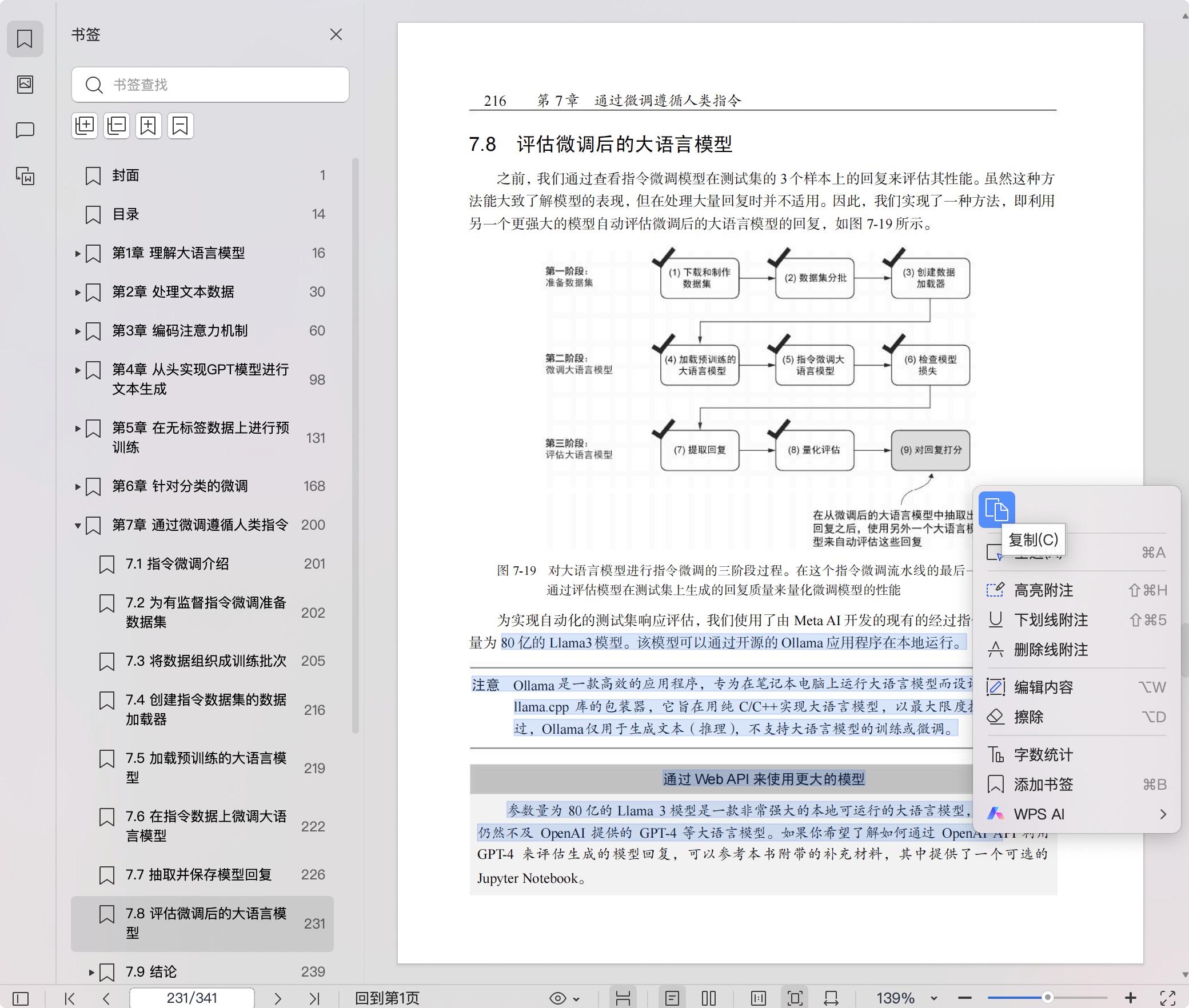
7.8 评估微调后的大语言模型 216
7.9 结论 224
7.10 小结 225
点击下载