
Python编程:从数据分析到数据科学pdf百度网盘下载地址?
朝乐门老师的《Python编程:从数据分析到数据科学(原稿)》作为全国高校大数据教育联盟主办的“Python编程及数据分析骨干教师高级研修班”的指定教材,得到与会代表的一致好评。该教材较好地反映了本学科的基本理论、基本知识、基本技能,并注重知识体系的系统性、科学性和先进性,对于大数据类专业中开设Python编程课程具有重要的示范意义和指导作用。—— 全国高校大数据教育联盟
作者简介:
朝乐门,1979年生,中国人民大学数据工程与知识工程教育部重点实验室、信息资源管理学院副教授,博士生导师;章鱼大数据首席数据科学家;中国计算机学会信息系统专委员会委员、ACM高级会员、国际知识管理协会正式委员、全国高校大数据教育联盟大数据教材专家指导委员会委员;主持完成国家自然科学基金、国家社会科学基金等重要科学研究项目10余项;参与完成核高基、973、863、国家自然科学基金重点项目、国家社会科学基金重大项目等国家重大科研项目10余项;获得北京市中青年骨干教师称号、国际知识管理与智力资本杰出成就奖、Emerald/EFMD国际杰出博士论文奖、国家自然科学基金项目优秀项目、中国大数据学术创新奖、中国大数据创新百人榜单、中国人民大学优秀博士论文奖等多种奖励30余项。朝乐门是我国第一部系统阐述数据科学理念、理论、方法、技术和工具的重要专著——《数据科学》... 朝乐门,1979年生,中国人民大学数据工程与知识工程教育部重点实验室、信息资源管理学院副教授,博士生导师;章鱼大数据首席数据科学家;中国计算机学会信息系统专委员会委员、ACM高级会员、国际知识管理协会正式委员、全国高校大数据教育联盟大数据教材专家指导委员会委员;主持完成国家自然科学基金、国家社会科学基金等重要科学研究项目10余项;参与完成核高基、973、863、国家自然科学基金重点项目、国家社会科学基金重大项目等国家重大科研项目10余项;获得北京市中青年骨干教师称号、国际知识管理与智力资本杰出成就奖、Emerald/EFMD国际杰出博士论文奖、国家自然科学基金项目优秀项目、中国大数据学术创新奖、中国大数据创新百人榜单、中国人民大学优秀博士论文奖等多种奖励30余项。朝乐门是我国第一部系统阐述数据科学理念、理论、方法、技术和工具的重要专著——《数据科学》(清华大学出版社,2016)的作者,也是数据科学与大数据技术专业第一个领域本体“DataScienceOntology”研发团队的总负责人。
目录:第一篇 准备工作
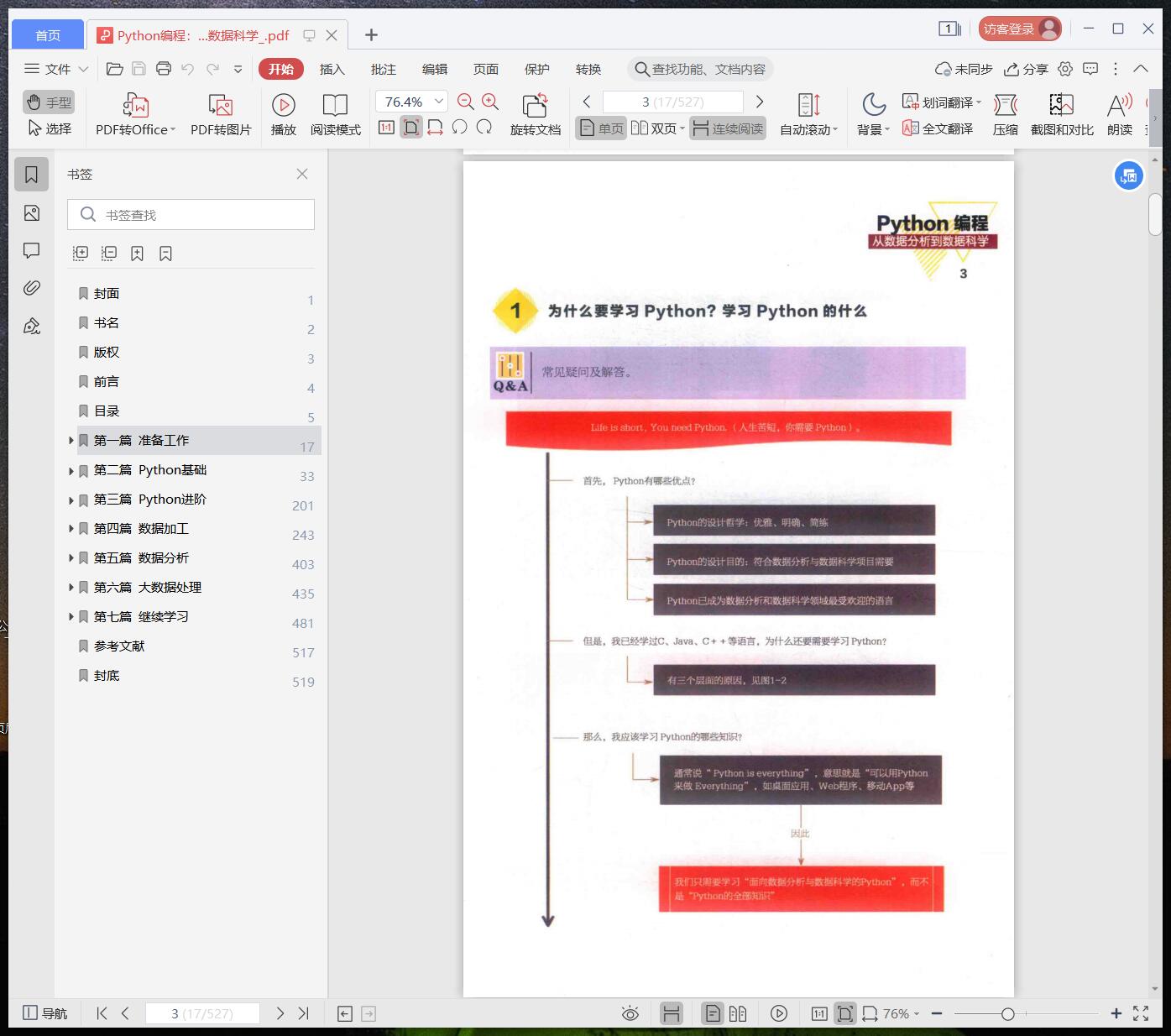
1 为什么要学习Python?学习Python 的什么 3
2 学习Python 之前需要准备的工作有哪些 6
3 如何看懂和运行本书代码 8
31 输入部分8
32 输出部分 10
33 错误与异常信息 11
34 外部数据文件12
35 注意事项 14
第二篇 Python基础
4 数据类型19
41 查看数据类型的方法 20
42 判断数据类型的方法21
43 数据类型的转换方法22
44 特殊数据类型23
45 序列类型26
5 变量28
51 变量的定义方法29
52 Python 是动态类型语言29
53 Python 是强类型语言 30
54 Python 中的变量名是引用31
55 Python 中区分大小写32
56 变量命名规范32
57 iPython 的特殊变量33
58 查看Python 关键字的方法 34
59 查看已定义的所有变量35
510 删除变量37
6 语句书写规范39
61 一行一句 40
62 一行多句 40
63 一句多行 41
64 复合语句 42
65 空语句 43
7 赋值语句44
71 赋值语句在Python 中的重要地位 45
72 链式赋值语句 45
73 复合赋值语句 46
74 序列的拆包式赋值 46
75 两个变量值的调换 47
8 注释语句48
81 注释方法 48
82 注意事项 49
9 运算符50
91 特殊运算符53
92 内置函数57
93 math 模块58
94 优先级与结合方向59
10 if语句61
101 基本语法61
102 elif 语句62
103 if 与三元运算63
104 注意事项 64
11 for语句67
111 基本语法67
112 range函数67
113 注意事项68
12 while语句71
121 基本语法71
122 注意事项72
13 pass语句74
131 含义 74
132 作用75
14 列表76
141 定义方法78
142 切片操作79
143 反向遍历81
144 类型转换83
145 extend 与append 的区别83
146 列表推导式 84
147 插入与删除87
148 常用操作函数89
15 元组94
151 定义方法95
152 主要特征97
153 基本用法99
154 应用场景 100
16 字符串 103
161 定义方法 104
162 主要特征 105
163 字符串的操作 106
17 序列111
171 支持索引 112
172 支持切片 113
173 支持迭代 114
174 支持拆包 114
175 支持*运算 115
176 通用函数 117
18 集合 120
181 定义方法 121
182 主要特征 122
183 基本运算 123
184 应用场景 125
19 字典126
191 定义方法 127
192 字典的主要特征 128
193 字典的应用场景 129
20 迭代器与生成器 130
201 可迭代对象与迭代器 131
202 生成器与迭代器 132
21 函数 134
211 内置函数135
212 模块函数135
213 用户自定义函数136
22 内置函数137
221 内置函数的主要特点 138
222 数学函数 138
223 类型函数 139
224 其他功能函数 140
23 模块函数 145
231 import 模块名 146
232 import 模块名as 别名 147
233 from 模块名import 函数名 147
24 自定义函数 149
241 定义方法 151
242 函数中的docString 152
243 自定义函数的调用方法 152
244 返回值 153
245 自定义函数的形参与实参 154
246 变量的可见性 156
247 值传递与地址传递 158
248 自定义函数时的注意事项 160
25 lambda 函数162
251 lambda 函数的定义方法 163
252 lambda 函数的调用方法 164
26 模块166
261 导入与用法 167
262 查看内置模块清单的方法 168
27 包171
271 包的基本术语 172
272 安装包 172
273 查看已安装包 173
274 更新(或删除)已安装包 173
275 导入包 174
276 查看包的帮助 175
277 常用包 176
28 帮助文档177
281 help 函数 178
282 DocString 178
283 查看源代码 179
284 doc 属性 180
285 dir函数 181
286 其他方法 183
第三篇 Python进阶
29 异常与错误187
291 try/except/finally 188
292 异常信息的显示模式 189
293 断言 190
30 程序调试方法192
301 调试程序的基本方法 193
302 设置错误信息的显示方式 194
303 设置断言的方法 195
31 面向对象编程197
311 类的定义方法 198
312 类中的特殊方法 199
313 类之间的继承关系 201
314 私有属性及@property 装饰器 203
315 self 和cls 204
316 new 与init 的区别和联系 205
32 魔术命令 208
321 运行py 文件:%run 209
322 统计运行时间:%timeit 与%%timeit 210
323 查看历史In 和Out 变量:%history 211
324 更改异常信息的显示模式:%xmode 212
325 调试程序:%debug 214
326 程序运行的逐行统计:%prun 与%lprun 215
327 内存使用情况的统计:%memit 216
33 搜索路径218
331 变量搜索路径 219
332 模块搜索路径 221
34 当前工作目录224
341 显示当前工作目录的方法 225
342 更改当前工作目录的方法 225
343 读、写当前工作目录的方法 226
第四篇 数据加工
35 随机数229
351 一次生成一个数 230
352 一次生成一个随机数组 231
36 数组234
361 创建方法 238
362 主要特征 241
363 切片/读取 243
364 浅拷贝和深拷贝 249
365 形状和重构 250
366 属性计算 254
367 ndarray 的计算 256
368 ndarray 的元素类型 258
369 插入与删除 259
3610 缺失值处理 260
3611 ndarray 的广播规则 261
3612 ndarray 的排序 262
37 Series 265
371 Series 的主要特点 266
372 Series 的定义方法 266
373 Series 的操作方法 269
38 DataFrame274
381 DataFrame 的创建方法 277
382 查看行或列 278
383 引用行或列 279
384 index 操作 283
385 删除或过滤行/列 285
386 算术运算 290
387 大小比较运算 296
388 统计信息 297
389 排序 299
3810 导入/导出 301
3811 缺失数据处理 302
3812 分组统计 308
39 日期与时间311
391 常用包与模块 312
392 时间和日期类型的定义 312
393 转换方法 314
394 显示系统当前时间 316
395 计算时差 317
396 时间索引 317
397 period_range函数 320
40 可视化321
401 Matplotlib 可视化 323
402 改变图的属性 326
403 改变图的类型 329
404 改变图的坐标轴的取值范围 330
405 去掉边界的空白 332
406 在同一个坐标上画两个图 333
407 多图显示 334
408 图的保存 335
409 散点图的画法 335
4010 Pandas 可视化 336
4011 Seaborn 可视化 339
4012 数据可视化实战 343
41 自然语言处理346
411 自然语言处理的常用包 347
412 自然语言处理的包导入及设置 347
413 数据读入 348
414 分词处理 349
415 自定义词汇 350
416 停用词处理 354
417 词性分布分析 356
418 高频词分析 358
419 词频统计 360
4110 关键词分析 362
4111 生成词云 363
42 Web爬取365
421 Scrapy 的下载与安装 367
422 Scrapy Shell 的基本原理 368
423 Scrapy Shell 的应用 370
424 自定义Spider 类 374
425 综合应用 379
第五篇 数据分析
43 统计分析389
431 业务理解 390
432 数据读入 391
433 数据理解 392
434 数据准备 393
435 模型类型的选择与超级参数的设置 394
436 训练具体模型及查看其统计量 396
437 拟合优度评价 397
438 建模前提假定的讨论 398
439 模型的优化与重新选择 400
4310 模型的应用 404
44 机器学习 405
441 机器学习的业务理解 406
442 数据读入 407
443 数据理解 408
444 数据准备 411
445 算法选择及其超级参数的设置 414
446 具体模型的训练 415
447 用模型进行预测 415
448 模型评价 416
449 模型的应用与优化 417
点击下载