
本书是继《Easy RL:强化学习教程》(俗称“蘑菇书”)之后,为强化学习的读者专门打造的一本深入实践的全新教程。全书大部分内容基于3位作者的实践经验,涵盖马尔可夫决策过程、动态规划、免模型预测、免模型控制、深度学习基础、DQN算法、DQN算法进阶、策略梯度、Actor-Critic算法、DDPG与TD3算法、PPO算法等内容,旨在帮助读者快速入门强化学习的代码实践,并辅以一套开源代码框架“JoyRL”,便于读者适应业界应用研究风格的代码。与“蘑菇书”不同,本书对强化学习核心理论进行提炼,并串联知识点,重视强化学习代码实践的指导而不是对理论的详细讲解。
本书适合具有一定编程基础且希望快速进入实践应用阶段的读者阅读。
目录:
第 1 章 绪论 1
1.1 为什么要学习强化学习? 2
1.2 强化学习的应用 3
1.3 强化学习方向概述 6
1.4 学习本书之前的一些准备 8
第 2 章 马尔可夫决策过程 10
2.1 马尔可夫决策过程 10
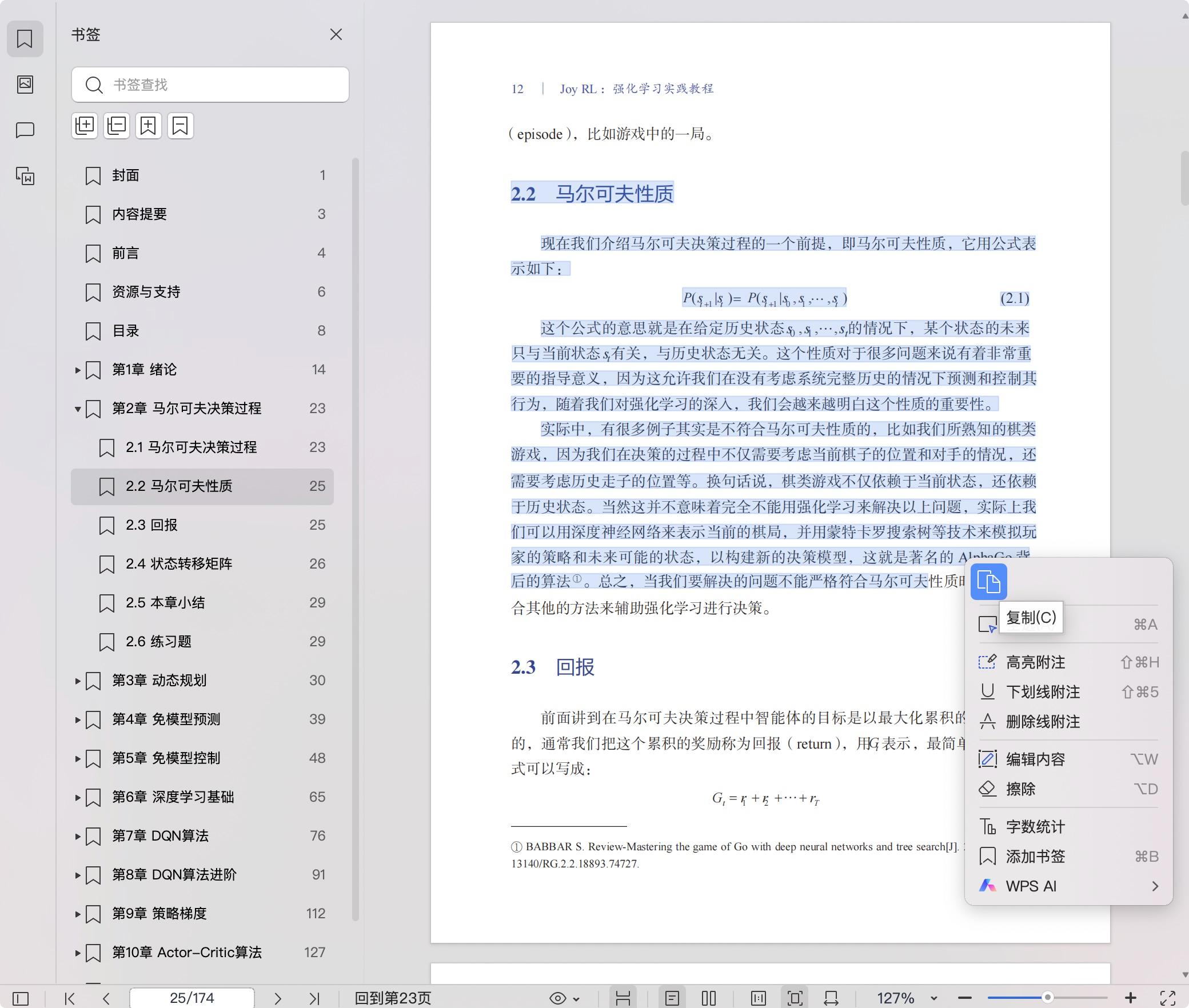
2.2 马尔可夫性质 12
2.3 回报 12
2.4 状态转移矩阵 13
2.5 本章小结 16
2.6 练习题 16
第 3 章 动态规划 17
3.1 动态规划的编程思想 17
3.2 状态价值函数和动作价值函数 20
3.3 贝尔曼方程 20
3.4 策略迭代算法 22
3.5 价值迭代算法 23
3.6 本章小结 25
3.7 练习题 25
第 4 章 免模型预测 26
4.1 有模型与免模型 26
4.2 预测与控制 27
4.3 蒙特卡罗方法 27
4.4 时序差分方法 30
4.5 时序差分方法和蒙特卡罗方法的差异 31
4.6 n 步时序差分方法 32
4.7 本章小结 33
4.8 练习题 34
第 5 章 免模型控制 35
5.1 Q-learning 算法 35
5.2 Sarsa 算法 39
5.3 同策略算法与异策略算法 40
5.4 实战:Q-learning 算法 .41
5.5 实战:Sarsa 算法 .50
5.6 本章小结 51
5.7 练习题 51
第 6 章 深度学习基础 52
6.1 强化学习与深度学习的关系 52
6.2 线性回归模型 55
6.3 梯度下降 56
6.4 逻辑回归模型 57
6.5 全连接网络 59
6.6 高级的神经网络模型 60
6.7 本章小结 62
6.8 练习题 62
第 7 章 DQN 算法 63
7.1 深度神经网络 63
7.2 经验回放 65
7.3 目标网络 67
7.4 实战:DQN 算法 68
7.5 本章小结 77
7.6 练习题 77
第 8 章 DQN 算法进阶 78
8.1 Double DQN 算法 78
8.2 Dueling DQN 算法 80
8.3 Noisy DQN 算法 81
8.4 PER DQN 算法 82
8.5 实战:Double DQN 算法 86
8.6 实战:Dueling DQN 算法 87
8.7 实战:Noisy DQN 算法 89
8.8 实战:PER DQN 算法 92
8.9 本章小结 98
8.10 练习题 98
第 9 章 策略梯度 99
9.1 基于价值的算法的缺点 99
9.2 策略梯度算法 100
9.3 REINFORCE 算法 104
9.4 策略梯度推导进阶 105
9.5 策略函数的设计 111
9.6 本章小结 112
9.7 练习题 113
第 10 章 Actor-Critic 算法 114
10.1 策略梯度算法的优缺点 114
10.2 Q Actor-Critic 算法 115
10.3 A2C 与 A3C 算法 116
10.4 广义优势估计 118
10.5 实战:A2C 算法 119
10.6 本章小结 123
10.7 练习题 123
第 11 章 DDPG 与 TD3 算法 124
11.1 DPG 算法 124
11.2 DDPG 算法 126
11.3 DDPG 算法的优缺点 128
11.4 TD3 算法 129
11.5 实战:DDPG 算法 131
11.6 实战:TD3 算法 136
11.7 本章小结 138
11.8 练习题 138
第 12 章 PPO 算法 139
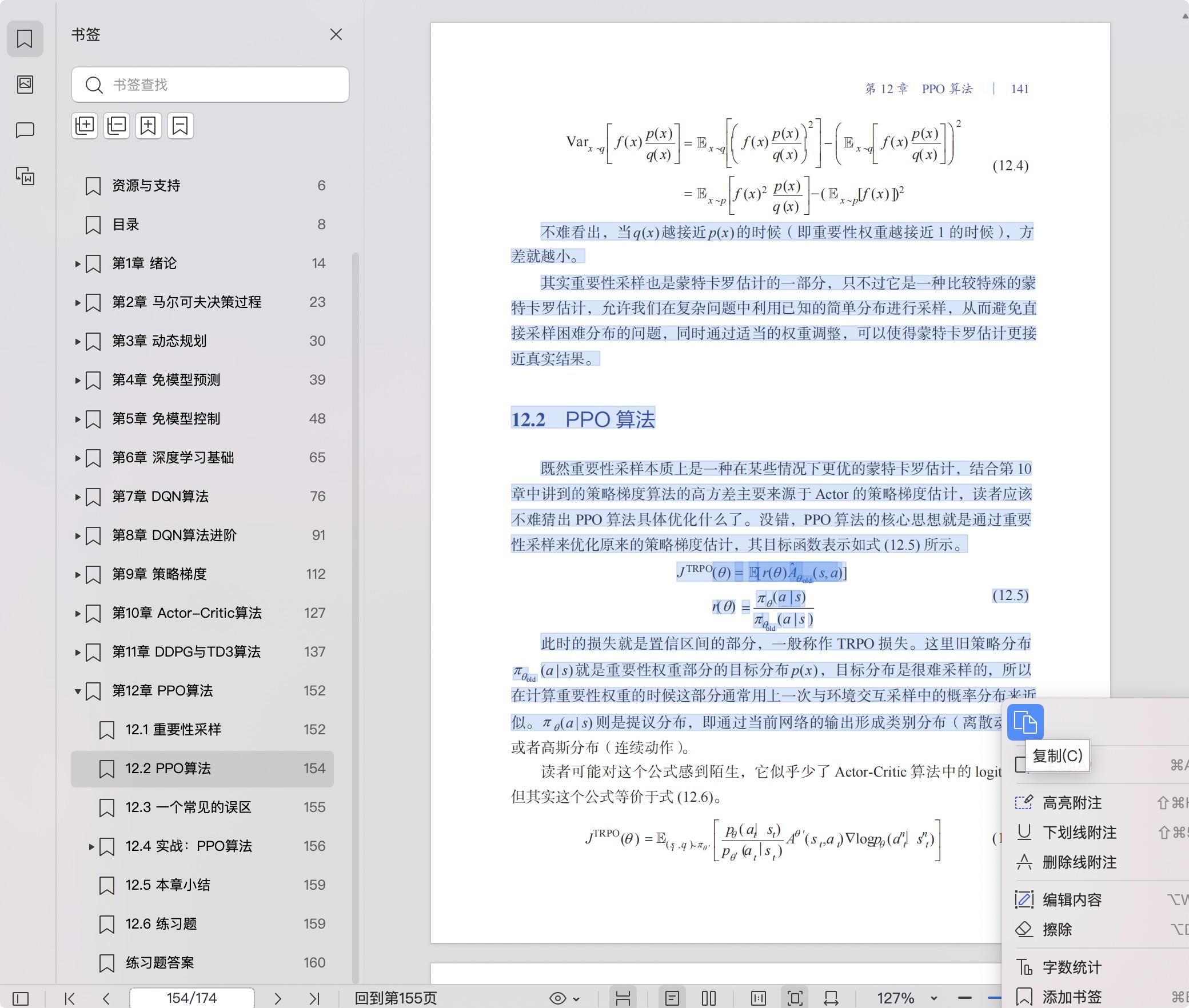
12.1 重要性采样 139
12.2 PPO 算法141
12.3 一个常见的误区 142
12.4 实战:PPO 算法.143
12.5 本章小结 146
12.6 练习题 146
练习题答案 147
点击下载